
This article was made as part of the NET2 course at EPITA. The final project was to write a technical article on a subject of our choice.

An Introduction to Kotlin Coroutines
In today’s world, many systems rely on high-performance asynchronous systems to survive and provide fast, critical services. Network is particularly important in this. Languages have tried to make these asynchrony and scalability requirements as easy to fulfill for the average programmer. While some have succeeded, some languages, such as Java, have remained significantly shy in that regard, not providing language features but library features, with classes and APIs to deal with those. These provide an unexceptional, clumsy and unintuitive experience for developers. Even for languages which do provide such features, they often end up not being universal or flexible enough to satisfy very special needs.
Kotlin1 is a cross-platform2, statically-typed3 programming language that mixes imperative, object-oriented and functional programming. It has become massively popular since its creation, mainly thanks to it becoming the preferred language for Android development4. It also had to answer the question of making high-performance and scalable systems tolerable for programmers. Its answer, Kotlin Coroutines are interesting in many ways, though they are not easy to apprehend.
They provide a unique perspective of the problem. The creators tried, from the very beginning, to implement a versatile solution that could solve more than just asynchrony. Today, coroutines are everywhere and are a must for any Kotlin programmer, but are also interesting for everyone else. They are a fascinating system that provide a clean developer experience, at the cost of a somewhat steep learning curve. They are used for asynchronous, scalable code, but also to implement the yield feature found in many languages or even deeply nested functions thanks to the versatile system that makes them tick.
Coroutines have made quite a splash in the JVM world, being one of the first coroutines system to have such a big impact on the ecosystem. Not only do they provide fairly obvious benefits to anyone wanting to work with asynchronous code in Kotlin, Kotlin Coroutines also gave way to new data structures based around the foundational concept behind them: suspending functions.
This article provides a concise but complete introduction to the world of Kotlin coroutines.
In order to understand why Kotlin coroutines are the way they are, it is useful to check out the other systems that were available around it, especially on the JVM.
A Primer on Asynchronous Programming
Asynchrony is the ability to launch “background actions” independent of the main program flow. This means that, thanks to asynchronous programming, we can let our program do other things while it waits for an answer in the background. Asynchrony is related to threads, as threads are what allows us to run two things in parallel. Do remember though that asynchrony and parallelism are not the same thing5: asynchrony is about non-blocking operations and parallelism is about doing multiple things at the same time.
Here is an example of what we call blocking code:
public getPrint(HttpRequest request) {
var client = HttpClient.newBuilder()
// Call functions on the builder to configure our client
.build();
var res = client.send(request); // [1]
System.out.println("I'm done!");
}
The main problem here is that our code will stay “stuck” at [1], meaning that we are not able to do anything while we wait for the response. If we want to do something else while our request is being processed, we need to use asynchrony: launch the request in the background, do other things, then we’re done.
public getPrint(HttpRequest request) {
var client = HttpClient.newBuilder()
// Call functions on the builder to configure our client
.build();
var res = client.sendAsync(request, BodyHandlers.ofString());
System.out.println("Request sent...");
// res... wait, what is res here?
}
Alright, good, our request is now ran in the background, but… how the hell do I get the result now?
There are many ways to handle the result of an asynchronous operation.
Callbacks
The simplest version. When the operation is done, the background task will call a function or a lambda we provide. In this example, we want to:
- Call
http://example.com/one, which returns some body. - Call
http://example.com/special/XYZ, where XYZ is the body we received in the previous call. This call also returns a body. - Call
http://example.com/final/ABC, where ABC is the body we received in the previous call.
Here is an example on a fictional HTTP client:
// The callback in the argument allows the caller to decide what to do, e.g.
// sendAllRequests(result -> System.out.println("Hello!"));
public void sendAllRequests(Consumer<Result> callback) {
client.sendHttpAsync("http://example.com/one", resultOne -> {
var newUrl = "http://example.com/special/" + resultOne.getBody();
client.sendHttpAsync(newUrl, resultTwo -> {
var yetAnotherUrl = "http://example.com/final/" + resultTwo.getBody();
return client.sendHttpAsync(yetAnotherUrl, callback);
});
});
}
Welcome to callback hell6! Each additional request increments our block of code and does not look particularly clean, especially if we need to perform other asynchronous operations.
Handling exceptions cleanly is also a pain, as there is no way to catch what happens within sendHttpAsync which, remember, is ran on a completely different thread. We would thus have to register a “special lambda” with the client or some other error recovery mechanism.
Functional Composition (CompletableFuture)
A common method is to deal with the results of asynchronous operations is to deal with them similarly to a Java stream, where you progressively change the value with each function call. This provides a flexible system. Here is the same example rewritten with Java’s CompletableFuture7 functionality via a (simplified) HttpClient class8.
// Same usage as in the callback example
public void sendAllRequests(Consumer<Result> callback) {
var client = HttpClient.newBuilder()
// Call functions on the builder to configure our client
.build();
client.sendAsync("http://example.com/one", BodyHandlers.ofString())
// Second call
.thenMap(result -> "http://example.com/special/" + result.getBody())
.thenCompose(url -> client.sendAsync(url, BodyHandlers.ofString()))
// Third call
.thenMap(result -> "http://example.com/final/" + result.getBody())
.thenCompose(url -> client.sendAsync(url, BodyHandlers.ofString()))
// Call the callback with the end result
.thenAccept(result -> callback.invoke(result));
}
This is cleaner than the callback exception as we do not end up with a billion nested lambdas. CompletableFuture instances represent “something that is going on in the background”, and can be easily transformed, composed and dealt with. We can also represent ourselves as a CompletableFuture, letting the caller to do whatever they want with the result and allowing them to do other things via the CompletableFuture chain.
// Example usage:
// sendAllRequests().thenAccept(result -> System.out.println("Hi!"))
public CompletableFuture<Result> sendAllRequests() {
var client = HttpClient.newBuilder()
// Call functions on the builder to configure our client
.build();
return client.sendAsync("http://example.com/one", BodyHandlers.ofString())
// Second call
.thenMap(result -> "http://example.com/special/" + result.getBody())
.thenCompose(url -> client.sendAsync(url, BodyHandlers.ofString()))
// Third call
.thenMap(result -> "http://example.com/final/" + result.getBody())
.thenCompose(url -> client.sendAsync(url, BodyHandlers.ofString()));
}
Error handling is also made simpler, as CompletableFuture instances are able to propagate errors via the intermediate functions. There are a few ways for handling errors asynchronously (i.e. excluding blocking methods which just rethrow the exception).
-
With
exceptionallyfor handling exceptions within the pipeline itself -
With
handlefor handling both exceptions and regular values.
They also handle cancellations, which are just exceptions of type CancellationException
CompletableFuture is quite flexible. You can manually turn callback-based APIs into CompletableFuture based APIs by following this general system. Here is an example of integrating Unirest’s9 callback system into a CompletableFuture system. Unirest calls the completed, failed and cancelled functions of the callback object once it is done. The general idea is to call the CompletableFuture object’s complete, completeExceptionally and cancel in each of those cases.
private class UnirestCallback implements Callback<String> {
private final CompletableFuture<String> toComplete;
public UnirestCallback(CompletableFuture<String> completionHandler) {
toComplete = completionHandler;
}
@Override
public void completed(HttpResponse<String> response) {
toComplete.complete(httpResponse.getBody());
}
@Override
public void failed(UnirestException e) {
toComplete.completeExceptionally(e);
}
@Override
public void cancelled() {
toComplete.cancel(true);
}
}
public CompletableFuture<String> getAsync(String url) {
var completable = new CompletableFuture<String>();
Unirest.get(url).asStringAsync(new UnirestCallback(completable));
return completable;
}
Overall, this is a good system. It does have drawbacks:
- Maintaining state in-between calls is difficult and requires creating entire object representing the state of the procedures.
- The sheer number of
.thenXXXoperations that are required for complex operations can make understanding what the function actually does difficult.
Similar frameworks exist for flow-based operations, such as reactive streams10 or the Flow class in Java11.
Async/Await
Many languages support some form of the async/await pattern12 as keywords embedded in the language, most notably C#13, Python14 and JavaScript15. While the exact implementation depends on the program, this usually revolves around some concept of a coroutine and resuming execution somewhere.
Here is the same example from before, this time in Python using a (fake) library:
async def sendAllRequests():
res = await http.get("http://example.com/one")
res2 = await http.get("http://example.com/special/" + res.body)
res3 = await http.get("http://example.com/final/" + res.body)
The general powers of these systems are that:
- They are first party solutions embedded in the language. No additional libraries required!
- Are fairly easy to use: just mark it as
asyncandawaitstuff.
They do not come without cons:
- Introduces two hard keywords16 that could have been used before by other libraries before they were introduced to the language.
- It might not be obvious what part of the library is interesting for a specific use.
- The standard library may have tons of functions about them that cannot be extracted into a separate library.
Kotlin Coroutines
A coroutine17 in Kotlin is an instance of a suspendable computation. Let’s take an example.
Imagine that you and two friends want to finish 13 games on 13 separate Game Boy consoles at the same time. These games are regular console games, but will sometimes need to pause to do other things. This means that the three of you will need to play on the different consoles, switching to other ones when a pause is triggered, and “going back” to consoles that just resumed, until all of them are done. This means that, while there are 13 games, each on of you is not just stuck waiting for a game to resume, you are actively jumping between games.
Now, imagine that you and your friends are actually threads, that the consoles are coroutines and substitute “pausing” for “suspending”, and you now understand the basic principle behind coroutines. Coroutines are like tasks that have several points at which they can be paused while they wait for other stuff. Suspendable here just means that the task can be literally paused, carried around and spun back up later.
Kotlin does all of this using suspending functions (suspend fun instead of just fun), which are special functions that have the ability to call other suspending functions and to save their internal state (similar to a stack frame) and resume execution later, directly jumping to the point in their body where they left off. This is implemented using a state-machine.
Kotlin coroutines are quite similar to coroutines in other languages, with some design differences:
-
Kotlin Coroutines (and more specifically the suspending functions) are designed to be extremely versatile.
-
They do not require any keyword other than
suspend, everything else is implemented as regular Kotlin functions. -
They do not rely on any particular library to do their work – in fact, most of the functionality related to coroutines is provided in a separate library named
kotlinx.coroutineswith only essential abstract data structures being bundled in the standard library.
Here is an example of asynchrony using coroutines:
suspend fun makeRequests(client: HttpClient): String {
val resultOne = client.sendRequest("http://example.com/one")
val urlTwo = "http://example.com/special/" + resultOne.body
val resultTwo = client.sendRequest(urlTwo)
val finalUrl = "http://example.com/final/" + resultTwo.body
val finalResult = client.sendRequest(finalUrl)
return finalResult.body
}
Some notes about this code for those who do not know Kotlin:
-
“Real” getters are generally avoided in Kotlin and replaced by properties (e.g.
result.getBody()becomesresult.body) -
Types are declared after the name of the variable/parameter, e.g.
name: Typeand notType name
Suspend the fun!
Functions can be marked as suspending functions using the suspend keyword. This means that the function contains suspension points, points in the function where the function can be paused. Concretely, this means extracting the state from the running function and being able to resume said running function by just giving it its state back.
Suspension points are identified by a small arrow struck by a green wave icon in the gutter in IntelliJ IDEA.
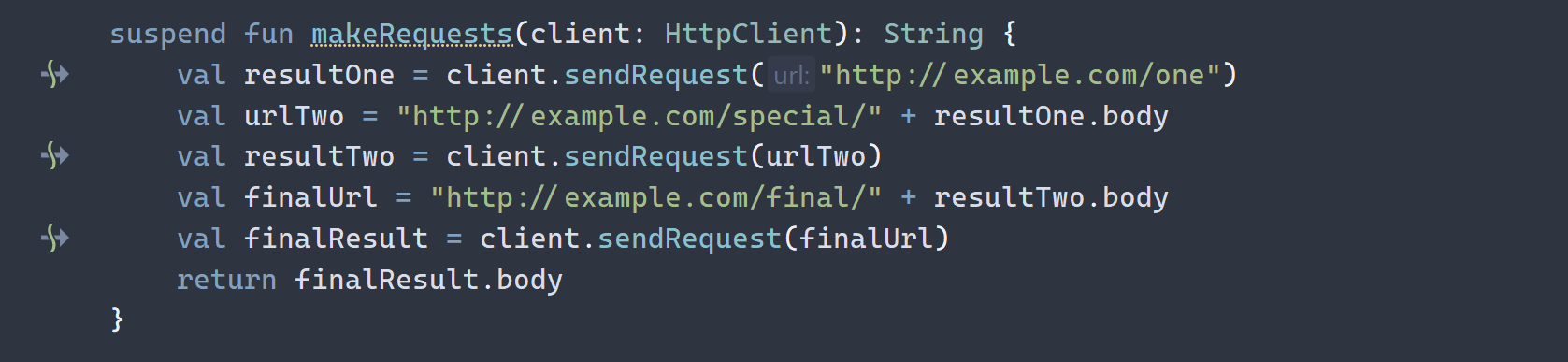
Obviously, if a function is simple enough for it to not have suspension points, it must not be a suspending function, as otherwise useless constructs would be created.
There are a few rules that must be respected about them:
-
Suspending functions may only be called from suspending functions, suspending lambdas or inlined18 into a suspending function or a suspending lambda.
-
Blocking code must generally be avoided, except when ran in a context that is specifically designed for those cases.
Lambdas
Kotlin puts a lot of importance on lambdas19 to provide clean APIs. In order to understand what is going on with coroutines, we need to stop and explain a few concepts about Kotlin lambdas.
Lambdas in Kotlin have this shape:
val someLambda = { x: XType, y: YType ->
println("Hello")
// In Kotlin, the return value in a lambda is the last expression
// So you can think of this as "return x + z"
x + z
}
// Types can be omitted if they can be guessed from context
// (in this case explicitly defining the type of the variable)
val someLambda2: (Int, String) -> Int = { theInt, theString ->
// ...
}
Last lambda parameter
In Kotlin, repeating an action 3 times can be done using a simple function:
repeat(4) {
println("Hello World!")
}
repeat is not a language keyword or anything, and this syntax is one of the most useful things Kotlin has. The code above is equivalent to:
// Regular lambda
repeat(4, { _ -> println("Hello World!") })
// In Kotlin, if the lambda takes no argument, you can omit the arrow
repeat(4, { println("Hello World!") })
So, what allows us to make that transformation? In Kotlin, the last lambda of a called function can be put next to the function20. This is why a lot of Kotlin lambda calls don’t look like lambdas at all. This functionality single-handedly makes functional programming in Kotlin significantly cleaner.
Note that, if the function does not take any argument other than the lambda, you can also omit the () entirely. Also, if the lambda only takes a single parameter, Kotlin implicitly names it it21. For example:
val list = listOf(1, 2, 3)
val doubled = list.map { it * 2 }
// list.map { x -> x * 2 } would also work
println(doubled)
// [2, 4, 6]
Extension functions and lambdas
Additionally, functions and lambdas can be extension functions and lambdas with receivers, meaning that they have an implicit this within their body.
Extension functions can be used to create useful add-ons to existing classes. For example, if we wanted to get the first three characters (or less) of a string as a list, we would write this:
fun String.firstThreeChars(): List<Char> {
// "length" is a String property, and provided with an implicit this
// We could also write this.length.xxx(), but we don't have to.
// coerceAtMost is an extension function on numbers that clamps them
// to the maximum value you give it.
val actualLength = length.coerceAtMost(3)
// substring is a String function, and can be accessed in the same way
val firstThreeStr = substring(0, actualLength)
// String -> Array<Char> -> List<Char>
return firstThreeStr.charArray().toList()
}
Lambdas with receivers are similar to extension functions in that their body has an implicit this, called the receiver.
fun doSomethingOnString(lambdaThatReceivesAString: String.() -> String) {
// ...
}
doSomethingOnString { toUpperCase() }
This allows for “scoped” things, builders, DSLs and so much more. For example, you could provide access to some service only within a specific lambda.
One of the consequences of extension functions and lambdas is that Kotlin generally pushes the single-responsibility principle22 to a significant extent: classes should only contain intrinsic properties and functions, and any other bonus functionality that only uses exposed intrinsic properties and functions should be declared as extension functions. This leads to cleaner, more readable classes without sacrificing completeness.
Suspending lambdas
Because lambdas in the context of coroutines can contain suspension points and regular puny lambdas do not have that superpower, suspending lambdas exist and are what suspending functions are compared to functions. Its type is declared like so:
// A lambda that takes no argument and returns a string
() -> String
// A lambda that takes two integers and returns a float
(Int, Int) -> Float
// A lambda that receives a string, takes an int and a float and
// returns a char
String.(Int, Float) -> Char
// A suspending lambda that takes no argument and returns a string
suspend () -> String
// A suspending lambda that takes two integers and returns a float
suspend (Int, Int) -> Float
// A lambda that receives a string, takes a long and returns a char
suspend String.(Long) -> Char
Context
Coroutines are ran within a specific context. A context is, at its core, just a map that is attached to a coroutine’s continuation information (i.e. additional information stored beside the function’s state when suspending). Contexts are rarely created by hand. You would usually create a context for your situation by adding multiple elements or other contexts with the + operator.
Contexts are a fairly low-level concept coroutines wise, and are much more useful when paired with structured concurrency.
Launching coroutines
There are many ways of launching coroutines. The task is made non-obvious by the fact that we have to move from the thread-based world into the coroutine based-world, and that just launching stuff in the background and never checking back on them is actively discouraged by the principles of structured concurrency that Kotlin coroutines (should) follow.
The simplest way is by using runBlocking, which creates an event-loop and blocks the thread it is running on.
fun main() {
runBlocking { // [1]
for (i in 1..1000) { // [2]
launch { // [3]
delay(500) // [4]
print("Hi from the coroutine world!")
}
}
println("Launched!")
}
println("Done!")
}
-
This is the call to
runBlocking, which takes a suspending lambda and blocks the current thread (the main thread here) by spawning an event-loop that will handle all of our suspending needs. -
Kotlin only has for-each loops! For loops are generally not required (and are generally abstracted away in higher-order functions), and if you do want to execute something on a range of numbers, you will generally use ranges like this.
1..1000means a range from 1 to 1000, both included. -
This creates and launches a new coroutine in the current scope. We’ll talk more about scopes in the structured concurrency part: for now, just know that
runBlockingprovides a coroutine scope within which we can create and run more coroutines. Moreover,launchreturns aJobobject that allows us to monitor, join or cancel the coroutine. -
delayis a suspending function that suspends the coroutines for the given amount of time (in milliseconds) and resumes it after that point.
Remember that suspending is not blocking. When delay is launched, what happens is that the coroutine is suspended and the underlying thread manager is told to resume the coroutine after the given amount of time. The exact mechanism used is generally platform and context dependent.
This code outputs:
Launched!
Hi from the coroutine world!
Hi from the coroutine world!
(997 other repetitions)
Hi from the coroutine world!
Done!
runBlocking blocks the execution of the current thread until all of the coroutines that have been launched inside of it are done.
Structured concurrency
Structured concurrency is one of the most important concepts in Kotlin Coroutines usage. The basic idea is that all coroutines are executed within a specific scope, and that scope is responsible for tracking the life of its children. This is a recursive process: the root scope is responsible for its child scopes, these child scopes are responsible for their own child scopes, etc.
Let’s take the following example:
fun main() {
runBlocking /* [0] */ {
for (i in 1..3) {
launch /* [1] */ {
launch /* [2] */ {
println("Hello ${i} first!")
}
launch /* [3] */ {
println("Hello ${i} second!")
}
}
}
}
}
This will print the following, not necessarily in the same order:
Hello 1 first!
Hello 2 second!
Hello 1 second!
Hello 3 first!
Hello 2 first!
Hello 3 second!
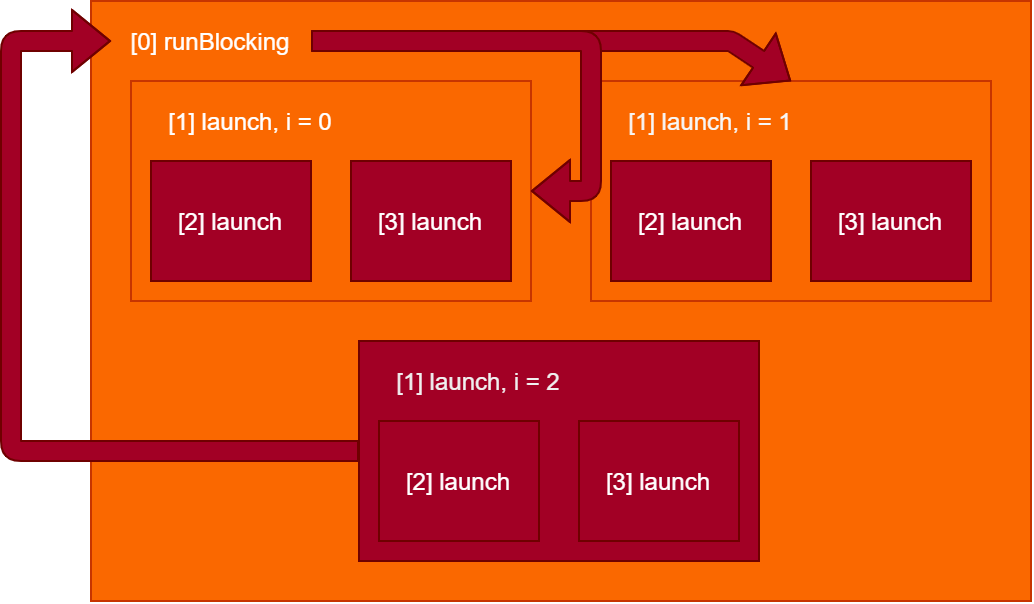
The nested scopes look like this:
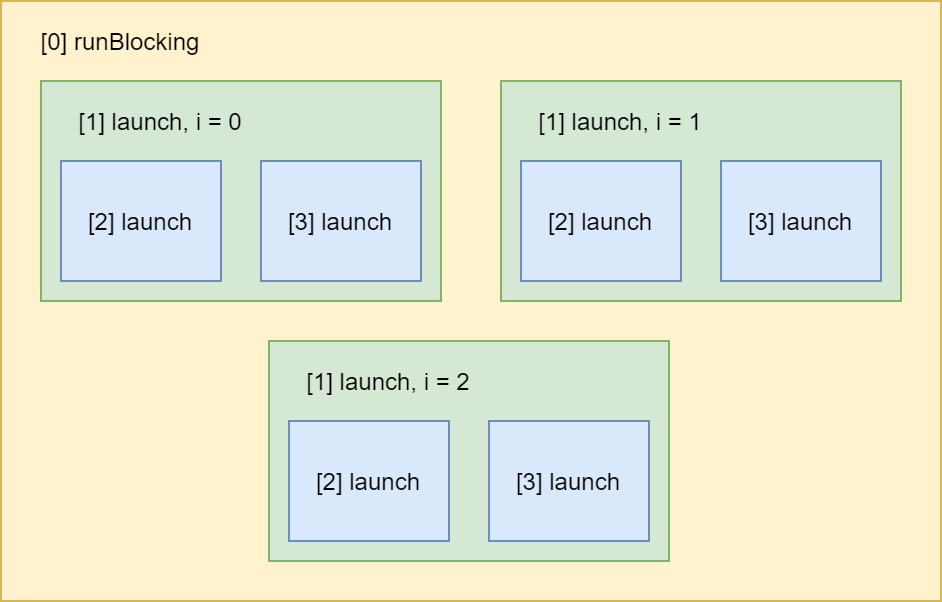
Each rectangle represents a coroutine. Every coroutine builder provides a scope within its lambda (i.e. launch { within here }) which can be used to launch other coroutines or perform asynchronous operations, which we will see later.
What would happen if one of those coroutines were to crash with an exception? Well, let’s see. Let’s say that in [1] launch when i = 2, the coroutine launched at [3] were to fail with an exception.
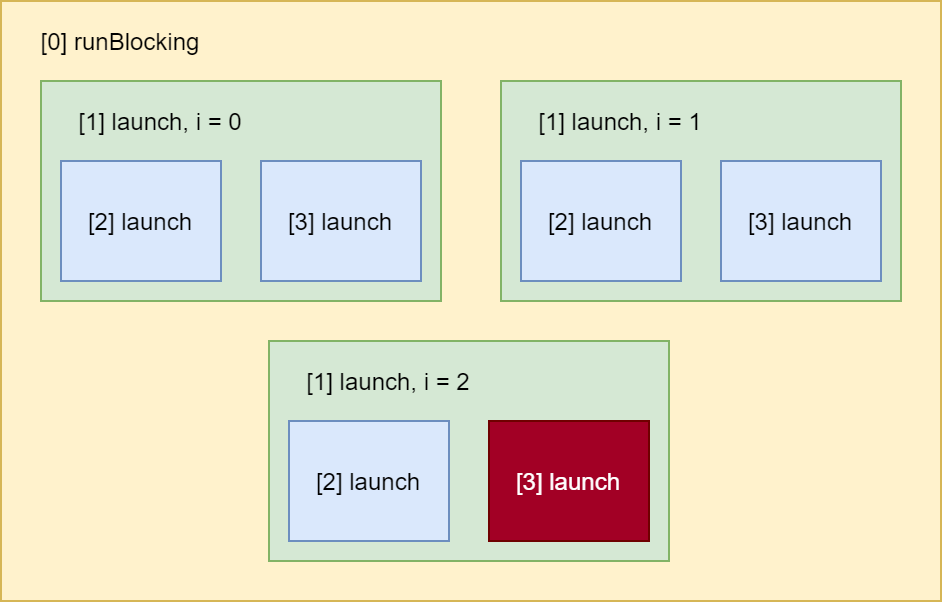
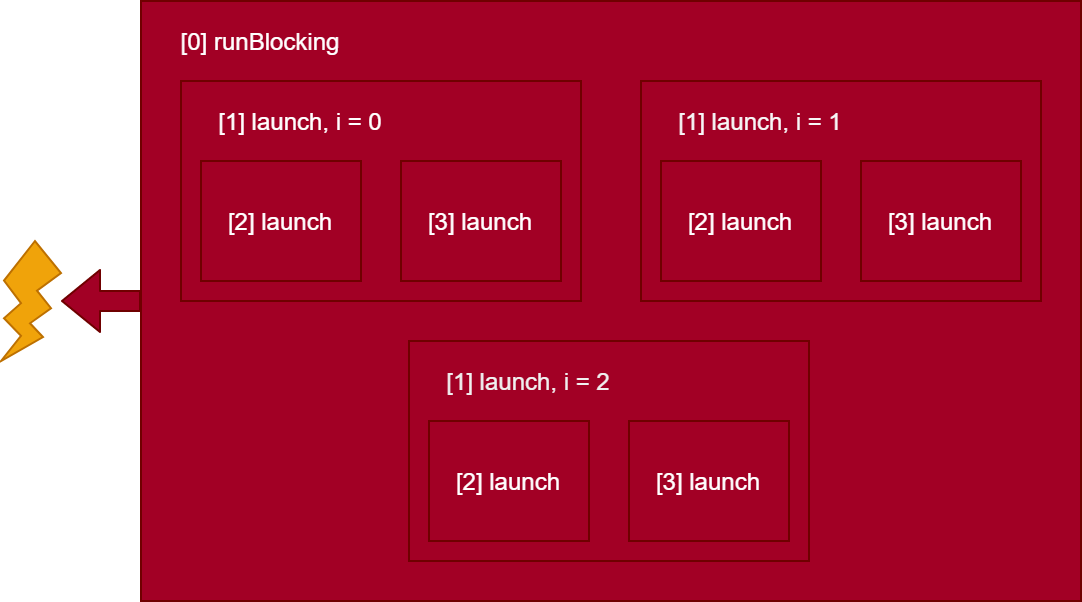
The parent of this coroutine gets notified (in orange) that one of its children has failed. Because of (or thanks to) structured concurrency, by default, jobs will cancel all of their other children when one of them fails.
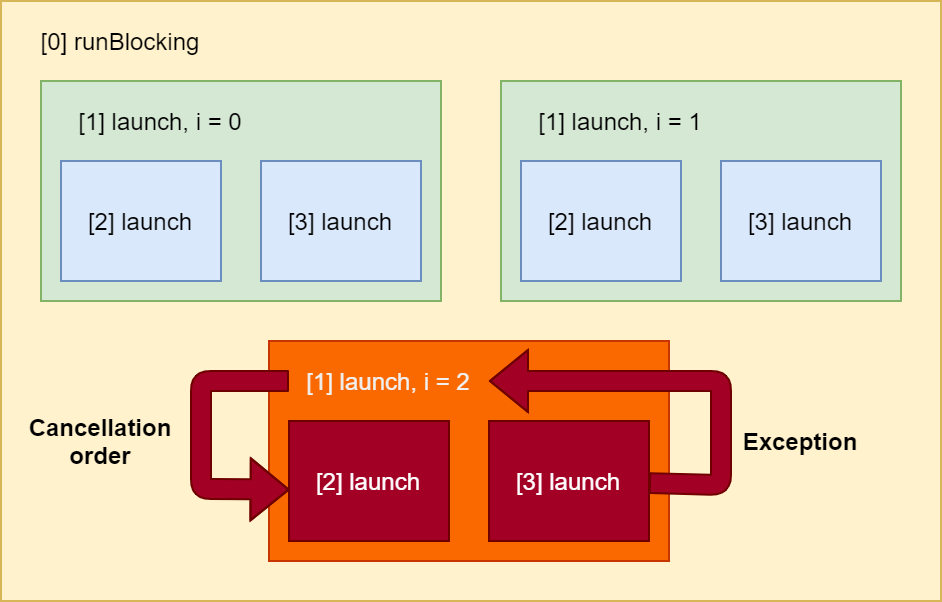
Once the coroutine scope has cancelled its children, it then kills itself and propagates the event to its parent, in this case [0] runBlocking, which in turn cancels all of its other children before terminating itself.
This time, because we are returning to the real world, this will be done with a regular exception throw (possibly wrapped with other coroutine exception types).
In short: structured concurrency makes handling exceptions safer by cancelling everything. Structured concurrency strongly enforces a concept of scoped and hierarchy, and avoids having coroutines leak, i.e. coroutines being launched into the stratosphere and never being monitored afterwards.
Async/Await
An example of where structured concurrency shines is with Kotlin Coroutines’ version of async/await. Consider that we want to load two text files and merge their content via a simple concatenation. Consider that we already have a loadFile suspending function that properly loads the file for us. One way to do it is:
suspend fun loadAndMergeTexts(fileOne: String, fileTwo: String) {
val firstText = loadFile(fileOne)
val secondText = loadFile(fileTwo)
// firstText and secondText are strings
return firstText + secondText
}
However, this is somewhat inefficient, as while we are loading the texts asynchronously (by just using coroutines and suspending functions), we could instead decide to load them in parallel.
As Kotlin only has a single keyword for coroutines (suspend), async and await are just regular suspending Kotlin functions!
-
async { ... }takes a lambda, executes it in the background and wraps the result using aDeferred<T>23 object. -
.await()is a function available onDeferred<T>objects but also on other objects from other (usually reactive) frameworks and suspends until the object underlying object becomes available or when the underlying operation fails with an exception (in which case it rethrows that exception).
Sounds good, let’s write all of this in code:
// THIS IS WRONG DO NOT DO THIS
suspend fun loadAndMergeTexts(fileOne: String, fileTwo: String): String {
val firstText = async { loadFile(fileOne) }
val secondText = async { loadFile(fileTwo) }
// firstText and secondText are Deferred<String> objects
return firstText.await() + secondText.await()
}
So, what could possibly go wrong here? Let me answer that question with another question: what happens when one of the lambdas in async fails? Roman Elizarov, who was the lead for Kotlin libraries before becoming the project lead for Kotlin in 2020, thought of a few of them for us:24
-
This function will probably be called as part of a larger coroutine. What happens if, at any point, this parent coroutine gets cancelled or fails in any other way? How can our function know about this?
-
What if either of the code in the async blocks fail? If the second one fail, that’s not really a problem, as we will have called
.await()on both of them if we get to this point. But what about the first one? If thefirstTextasynchronous logic fails, thesecondTextlogic will still keep going behind the scenes, and we have no way of stopping it!
You may have noticed a trend here: we want to be able to stop our coroutines when children fail… This is pretty much exactly what the code in the previous section was doing!
Structured concurrency to the rescue!
In reality, async requires to be within a CoroutineScope, as it is an extension function over CoroutineScope. However, receiving a scope from a parent would be a pain: we must instead use coroutineScope { ... }, like so:
suspend fun loadAndMergeTexts(fileOne: String, fileTwo: String): String {
return coroutineScope {
val firstText = async { loadFile(fileOne) }
val secondText = async { loadFile(fileTwo) }
firstText.await() + secondText.await()
}
}
The extra indentation is a bit annoying as this is a pretty common use case, so we can instead use Kotlin’s single-expression function feature to save on the indentation tax:
suspend fun loadAndMergeTexts(/* ... */) = coroutineScope {
val firstText = async { loadFile(fileOne) }
val secondText = async { loadFile(fileTwo) }
firstText.await() + secondText.await()
}
coroutineScope suspends until all of the coroutines launched inside of it finish (including async stuff). This ensures that no coroutines are left behind, and avoids coroutine leakage.
Scopes attached to things
It is also possible for “components” to have an innate scope, which is managed at an object level instead of at the function level. This is especially useful for things that have a defined lifecycle, such as UI elements on Android.
This is usually done by just declaring a property in the class where you want to have a coroutine scope:
class MyComponent {
private val scope = CoroutineScope()
fun launchSomethingInTheBackground() {
scope.launch {
delay(1000)
println("Hi!")
}
}
}
Note that this scope follows the general rules of coroutine scopes, including the fact that if one of the coroutines fail, this scope will not recover and will cancel itself and its children. In order to circumvent this, you will need context elements.
Cancellation
As previously mentioned, Kotlin coroutines can be cancelled25. Cancelling a coroutine simply means throwing a CancellationException26. All of the functions from the standard Kotlin library and the kotlinx.coroutines library properly check for and apply cancellation order. If doing a lot of work yourself without using said functions, you will need to properly anticipate for the possibility of cancellation: it is a “cooperative” system. Refer to the documentation for more details on this topic.
Context Elements
The Kotlin coroutines library provides a few useful context elements that can be used to better manage what is going on.
These elements can be provided on a few places. One way is passing those elements in the parameters of a coroutine builder like launch. Remember that elements need to be combined using the + operator.
withContext(/* context here */) {
// code here will be ran in the given context
}
Let’s see some useful context elements…
Jobs
Jobs, which I have already mentioned before, are “cancellable things with a life-cycle that culminates in its completion”.
Jobs27 are the main tool used for structured concurrency:
- It encompasses some background action. This background action can be observed via multiple methods.
- It contains children jobs. A job only completes when all of the children jobs have completed.
- It can be cancelled, in which case they cancel their children.
Jobs are a core part of coroutines in the kotlinx.coroutines library, but not in the core standard library coroutine support. Not all coroutines can be represented as a job: for example, the yield mechanism is not a job in itself.
Jobs exist in multiple variants. The main one is CompletableJob28, which also maintains state on the completion status of the job (whether it is started, finished, cancelled, etc.).
Jobs are usually not manually interacted with, as higher level functions internally manage the jobs, although they are useful for checking what is actually going on with some background task.
Jobs themselves are only useful for their side effects, as they do not return a value. Deferred is a subtype of Job, and are what we can think of in terms of “a background action that eventually returns a thing”.
Dispatcher
Dispatchers29 are elements that dictate where (i.e. on which thread) a coroutine should be ran. This is extremely useful for UI frameworks which require UI operations to be made on a specific thread, or for making sure that you run your code in a specific context.
When executed, a suspending function or lambda executes in whatever the original dispatcher of the caller is. However, if given a specific dispatcher via a context element, it will be ran using that dispatcher. Dispatchers can be anything from single-thread executors to thread pools. If using a thread pool, dispatchers allow for parallelism (i.e. since it has multiple threads, coroutines scheduled on that dispatcher can be executed at the same time).
Dispatchers are available from the Dispatchers object. The main ones are:
-
Dispatchers.Default30, which, as its name suggests, is the default dispatcher used in a coroutine builder (likelaunchorasync) if the current context does not have a dispatcher. Using this dispatcher is recommended for CPU-intensive tasks and general purpose code. It is backed by a thread pool shared with other dispatchers. The maximum number of threads is the number of CPU cores, but is usually less than that.31 -
Dispatchers.IO32 is specifically built to handle blocking IO operations, meaning that this is the only case in which blocking code is tolerable. This dispatcher actually shares the same thread pool asDispatchers.Defaultbut does not handle threads the same way. Recent versions of Kotlin allow for dynamically resizing the thread pool to suit blocking task needs on the JVM.31 -
Dispatchers.Main33 is used for displaying UI objects. The exact thread this dispatches to depends on the environment34, and can dispatch to the Android Main thread dispatcher35, the JavaFX Application thread dispatcher36 or the Swing EDT dispatcher37. -
`Dispatchers.Unconfined
Here is an example of using different dispatchers:
// Just a utility function to make the example code less messy
fun printCurrentThread(prefix: Int) {
println("[$prefix] I'm in: " + Thread.currentThread().name)
}
fun main() {
printCurrentThread(1)
runBlocking { // Coroutine 1
printCurrentThread(2)
withContext(Dispatchers.Default) {
// Context changed, same coroutine
printCurrentThread(3)
}
launch { // Coroutine 2
// Same context, new coroutine
printCurrentThread(4)
}
launch(Dispatchers.IO) { // Coroutine 3
// Custom context, new coroutine
printCurrentThread(5)
withContext(Dispatchers.Default) {
// Changed context
printCurrentThread(6)
}
}
// Back in our regular coroutine
printCurrentThread(7)
}
}
Gives:
[1] I'm in: main
[2] I'm in: main @coroutine#1
[3] I'm in: DefaultDispatcher-worker-1 @coroutine#1
[7] I'm in: main @coroutine#1
[5] I'm in: DefaultDispatcher-worker-1 @coroutine#3
[4] I'm in: main @coroutine#2
[6] I'm in: DefaultDispatcher-worker-2 @coroutine#3
You can run this code here. Coroutine 1 corresponds to the coroutine created by runBlocking, coroutine 2 to the one created by the first launch and coroutine 3 by the second launch. We have three dispatchers in action here:
-
The implicit dispatcher in
runBlocking, which is used to run coroutine 1 and 2. Although we launched coroutine 2 before printing[7], this dispatcher is single threaded, meaninglaunchschedules coroutine 2 for later execution but cannot have it executed right now as it is still executing coroutine 1, which does not suspend from this point onwards. If coroutine 1 suspended at any point, the event loop behindrunBlockingwould be able to run coroutine 2 while coroutine 1 is suspended38. -
Dispatcher.Defaultis called usingwithContext. Unlikelaunch, which creates a new coroutine,withContextjust changes the context and executes the code in the context in the same coroutine. -
Dispatcher.IO(which uses the same thread pool asDispatcher.Default, hence the similar name) runs a separate coroutine which islaunched directly with the dispatcher.
Supervisor jobs
Supervisor jobs39 are Jobs that do not fail when a child coroutine fail. Specifically:
-
If a child coroutine fails or gets cancelled, only that coroutine fails.
-
If the parent of the supervisor job or the supervisor job itself gets cancelled, all children coroutines are cancelled.
A supervisor job’s only job is to not fail when children fail. If exceptions need to also be treated (as they often do), a few cases apply.
-
In the case of coroutines launched via
async, the failure can be handled where said coroutine isawaited via the usual try/catch -
For coroutines launched via
launch, the failure can be handled using aCoroutineExceptionHandler.
See in the next section for an example of a supervisor job.
CoroutineExceptionHandler
CoroutineExceptionHandler objects40 are elements that handle uncaught exceptions, i.e. exceptions that get propagated all the way up to the context. Note that this only works on coroutines that actually capture uncaught exceptions instead of passing them along, called “root” coroutines in the documentation. In almost all cases, you will want (or even need) to use this in conjunction with a SupervisorJob.
import kotlinx.coroutines.*
class VeryBuggy {
private val scope = CoroutineScope(Dispatchers.Default +
SupervisorJob() +
CoroutineExceptionHandler { _, ex ->
println("Oopsie " + ex.message)
}
)
fun launchSomething(message: String) {
scope.launch {
throw IllegalStateException(message)
}
}
}
fun main() {
val buggy = VeryBuggy()
buggy.launchSomething("Daisy!")
buggy.launchSomething("Woopsie!")
}
In this example, we create a scope using CoroutineScope(...)41, where ... contains the context element(s). Our context elements are:
-
Dispatchers.Default, which is not technically not necessary forlaunchas scopes that do not have a dispatcher default toDispatchers.Default. However, other commands, such asasync, may still keep their parent dispatcher from an outside caller, which may be a bad thing. -
SupervisorJob()which creates a supervisor job for the context, meaning that children coroutines failing will not cancel our scope, nor will it propagate to other children coroutines. -
CoroutineExceptionHandler { ... }is a function that creates aCoroutineExceptionHandler. When an exception occurs, the given lambda is executed with the coroutine’s context and the exception in the parameters.
You can run this code here. The output is:
Oopsie Daisy!
Oopsie Woopsie!
The order may be different (after all, this is the prime candidate for a race condition on the standard output). If you remove the SupervisorJob() + from the context creation, this is what happens:
Oopsie Daisy!
Because the scope does not have a supervisor job in its context anymore, the child coroutine fails (as expected), calls our exception handler, but also cancels the scope, meaning that subsequent calls on the scope will fail, sometimes silently, sometimes vocally, which is not exactly what we want.
Coroutine Utilities
Now that we’ve seen the basics of Kotlin’s coroutines, it’s time to see a few ways we can use them.
kotlinx.coroutines provides utility classes based on coroutines. The main idea is, in most cases, to provide suspending equivalents to data structures available in other libraries.
Flows
Flows42 are asynchronous data sequences that compute the values using suspension. Flows are lazy data streams (also known as cold streams): it only runs the generator code when required. They also progressively create each sequence value instead of generating them all at once (i.e. elements are created lazily on demand).
Flows are useful for sequences that are built and/or processed using suspending functions. They are suspending equivalents to Kotlin’s list and sequences. Here is an example:
fun makeTheFlow(): Flow<Int> = flow {
for (i in 1..5) {
delay(500)
emit(i)
}
}
fun main() {
runBlocking {
makeTheFlow().collect { println(it) }
}
}
This prints, with a half second delay before each number:
1
2
3
4
5
Flows support all of the usual coroutines shenanigans (cancellation, error handling, contexts, etc.) while providing all of the list-like operators you would expect (map, filter…). Note that most intermediary operations (i.e. non-terminal, things like filter and map that only change the pipeline logic) are not suspending functions, although they do take suspending lambdas! As they only modify the flow’s internal logic without actually triggering the flow’s internal generator, they do not need to be suspending.
To learn more about flows, including everything you can do with them, please refer to the Kotlin documentation.
Here is another example that takes the first 15 even numbers from the Fibonacci sequence:
fun fiboFlow() = flow {
emit(0)
emit(1)
var prev2 = 0
var prev = 1
while (true) {
val next = prev2 + prev
prev2 = prev
prev = next
emit(next)
}
}
fun main() {
runBlocking {
fiboFlow()
.withIndex()
.filter { (_, n) -> n % 2 == 0 }
.take(10)
.map { (i, n) -> "fibo($i) = $n" }
.collect { println(it) }
}
}
You can run this code here. This code outputs:
fibo(0) = 0
fibo(3) = 2
fibo(6) = 8
fibo(9) = 34
fibo(12) = 144
fibo(15) = 610
fibo(18) = 2584
fibo(21) = 10946
fibo(24) = 46368
fibo(27) = 196418
Flows do have restrictions, the main one being that emit can only be called in the original flow’s context.
Channels
Channels43 are the suspending version of BlockingQueue: a queue of things. There are two kinds of channels: send channels and receive channels. All of the queue-like functions are suspending.
- In send channels, the
sendfunction suspends if the queue’s internal buffer is full and resumes once the element has been added. - In receive channels, the
receivefunction suspends until something becomes available in the queue.
Channels are fully multi-threaded, meaning that multiple coroutines can send on or receive from the same channel.
Channels can be manually created and manually sent to or received from, or created using the produce functions, which takes a lambda and returns a channel which uses that lambda as a generator.
fun CoroutineScope.fibo() = produce<Int> {
send(0)
send(1)
var prev2 = 0
var prev = 1
while (true) {
val next = prev2 + prev
prev2 = prev
prev = next
send(next)
}
}
fun main() {
runBlocking {
val channel = fibo()
repeat(13) {
println(channel.receive())
}
channel.cancel() // [1]
}
}
You can run this code here. This code prints:
0
1
1
2
3
5
8
13
21
34
55
89
144
While this may seem more cumbersome than the flow system, remember that flows emissions are not thread safe, while you can send to/receive from channels from pretty much anywhere!
For more details about channels, please refer to the official documentation.
Yield in sequence generation
You may have noticed that in both previous examples, using flows or channels was not really necessary. None of the logic in making the Fibonacci sequence actually requires suspending at any point, although it makes for a great example. Kotlin provides a variant of flows that feature restricted suspension to provide a way of making sequences:
- That do not rely in any way on the
kotlinx.coroutineslibrary, making them available on all platforms where Kotlin is supported. - That is actually synchronous.
Restricted suspension is, in a nutshell, a kind of suspending lambda that is only able to call specific functions.
You may be wondering, well, if this is blocking code, what is the point of using a suspending thing? The answer is actually fairly simple. The yield mechanism44 exploits the state machine creation to maintain the state of where it is in the generator function. It is thus able to literally just pause when yielding something, and resuming exactly when it left of!
Here is the example from the flow mechanism, translated with the sequence { ... } builder45 instead.
fun fiboSequence() = sequence {
yield(0)
yield(1)
var prev2 = 0
var prev = 1
while (true) {
val next = prev2 + prev
prev2 = prev
prev = next
yield(next)
}
}
fun main() {
fiboSequence()
.withIndex()
.filter { (_, n) -> n % 2 == 0 }
.take(10)
.map { (i, n) -> "fibo($i) = $n" }
.forEach { println(it) }
}
You can run this code here. The result is:
fibo(0) = 0
fibo(3) = 2
fibo(6) = 8
fibo(9) = 34
fibo(12) = 144
fibo(15) = 610
fibo(18) = 2584
fibo(21) = 10946
fibo(24) = 46368
fibo(27) = 196418
This method does not require any special import, and is provides a clean, out-of-the-box sequence generation mechanism that does not actually use coroutines!
Deeply recursive functions
Deeply recursive functions46 are problematic in almost every programming language due to the limited size of the stack. While some techniques exist to alleviate this problem, such as tail recursion optimization (which is also available in Kotlin47), they do not work in every scenario, and you may end up being stuck with a function that does not work on large data structures. Kotlin, via the state-machine mechanism behind suspending functions, is able to prevent this by putting the stack on the heap by turning the recursion into a special continuation.
The underlying mechanism is quite complex and relies on internal Kotlin coroutine behavior, but you can check out Roman Elizarov’s blog post behind this feature. The mechanism he describes is currently available in Kotlin’s standard library as an experimental feature. Here is an example:
// A simple labeled tree class
data class Tree(val value: Int, val left: Tree?, val right: Tree?)
// Regular recursive function for computing the sum of all of the tree's
// nodes
fun computeSum(tree: Tree?): Int {
if (tree == null)
return 0 // Empty tree
val leftSum = computeSum(tree.left)
val rightSum = computeSum(tree.right)
return leftSum + rightSum + tree.value
}
// Special DeepRecursiveFunction
val computeSumDeep = DeepRecursiveFunction<Tree?, Int> { tree ->
if (tree == null) 0
else {
val leftSum = callRecursive(tree.left)
val rightSum = callRecursive(tree.right)
leftSum + rightSum + tree.value
}
}
// Generates a degenerate tree with 100k nodes
val hugeTree = generateSequence(Tree(1, null, null)) { Tree(1, it, null) }
.take(100_000).last()
fun main() {
runCatching {
println(computeSum(hugeTree))
}.onFailure { println("Failed!") }
runCatching {
println(computeSumDeep(hugeTree))
}
}
You can run this code here. This gives:
Failed!
100000
This solution is not perfect, as storing the stack frames on the heap does incur a significant performance penalty.
Conclusion
Kotlin Coroutines and the suspending mechanisms provided by the language are powerful tools that make asynchronous code easy to read and simpler to develop. Thanks to this system, it is quite easy to make asynchronous programs in Kotlin that scale well and remain reliable with the help of structured concurrency. With other features, such as the special lambda syntax, this provides a cohesive and, more importantly, pragmatic experience when coding in Kotlin. Kotlin’s suspension mechanism allows for the creation of more complicated utilities that rely on state machines (such as deep recursive functions) or pausing at some point in a function (such as the yield mechanism).
Coroutines thus make Kotlin one of the most useful languages for any development task which requires asynchronous programming in any way.
Bibliography
If you want to go further with Kotlin Coroutines, here are some links that may be of interest:
- Kotlin’s official documentation on coroutines
- Official design document, which has a lot of details about the internals of Kotlin coroutines.
- Ktor, JetBrains’ official HTTP server and client library that is designed from the ground up on and for coroutines.
Additional sources are available in the footnotes throughout the article.
A lot of research has been put into this article. Kotlin Coroutines have had a very steep learning curve for the longest time due to how different and sometimes unclear they feel.
-
Kotlin can be compiled to JVM byte-code (like Java) which in itself is cross-platform, but can also be transpiled to JavaScript or compiled to a native binary. See https://kotlinlang.org/docs/multiplatform.html ↩︎
-
This is not completely true. Kotlin/JS (i.e. Kotlin transpiled to JavaScript) supports the
dynamicobject, which disables all type-checking from the compiler and is mainly used for JavaScript interoperability. See also https://kotlinlang.org/docs/dynamic-type.html ↩︎ -
https://urda.com/blog/2010/10/04/asynchronous-versus-parallel-programming ↩︎
-
https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/concurrent/CompletableFuture.html ↩︎
-
Specifically, requests are supposed to be passed as
HttpRequestobjects, not just via a URL string. ↩︎ -
https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/concurrent/Flow.html ↩︎
-
https://developer.mozilla.org/fr/docs/Web/JavaScript/Reference/Statements/async_function ↩︎
-
Hard keywords are names that are always keywords and can never be interpreted as anything other than a keyword. For example, in many languages
voidis a hard keyword: you cannot name a function or a variable “void”. ↩︎ -
See here for the definitions for the Kotlin coroutines terminology. ↩︎
-
https://kotlinlang.org/docs/lambdas.html#passing-trailing-lambdas ↩︎
-
https://kotlinlang.org/docs/lambdas.html#it-implicit-name-of-a-single-parameter ↩︎
-
https://en.wikipedia.org/wiki/Single-responsibility_principle ↩︎
-
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-deferred/ ↩︎
-
https://elizarov.medium.com/structured-concurrency-722d765aa952 ↩︎
-
https://kotlinlang.org/docs/cancellation-and-timeouts.html ↩︎
-
https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.coroutines.cancellation/-cancellation-exception/ ↩︎
-
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/ ↩︎
-
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-completable-job/index.html ↩︎
-
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-dispatcher/index.html ↩︎
-
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-default.html ↩︎
-
This logic is primarily handled by an internal CoroutineScheduler class with quite complex behaviors. ↩︎ ↩︎
-
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-i-o.html ↩︎
-
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-main.html ↩︎
-
The main thread is chosen using the ServiceLoader mechanism on JVM with an additional dependency on a framework-specific coroutines library that both implements and exposes its implementation of
Dispatchers.Main. On all other platforms,Dispatchers.Mainis equivalent toDispatchers.Default. ↩︎ -
An additional dependency on
kotlinx-coroutines-androidis required. ↩︎ -
JavaFX is a modern UI framework for use on JVM. An additional dependency on
kotlinx-coroutines-javafxis required. ↩︎ -
Swing is the older (but not the oldest) UI framework for use on JVM. “EDT” means Event Dispatch Thread. An additional dependency on
kotlinx-coroutines-swingis required. ↩︎ -
This is typically what an event loop does, and what makes coroutines fairly efficient. You can see an example of this in action here (code itself here). ↩︎
-
Note that, technically speaking, there is no public class named
SupervisorJob, only a functionSupervisorJobthat returns a specialJob. See also the documentation for said function. ↩︎ -
Objects which are from the interface of the same name and are created using this function. ↩︎
-
CoroutineScopewith an uppercase ‘C’ creates a coroutine scope, whilecoroutineScopewith a lowercase ‘c’ creates a scope and runs provided lambda, then returns the lambda’s result. ↩︎ -
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow ↩︎
-
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-channel/ ↩︎
-
https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.sequences/sequence.html ↩︎
-
https://kotlinlang.org/api/latest/jvm/stdlib/kotlin/-deep-recursive-function/ ↩︎
-
A recursive function can be made tail recursive using the
tailreckeyword, see https://kotlinlang.org/docs/functions.html#tail-recursive-functions ↩︎